91.55% on LongMemEval, and the Benchmark I’m Building Instead
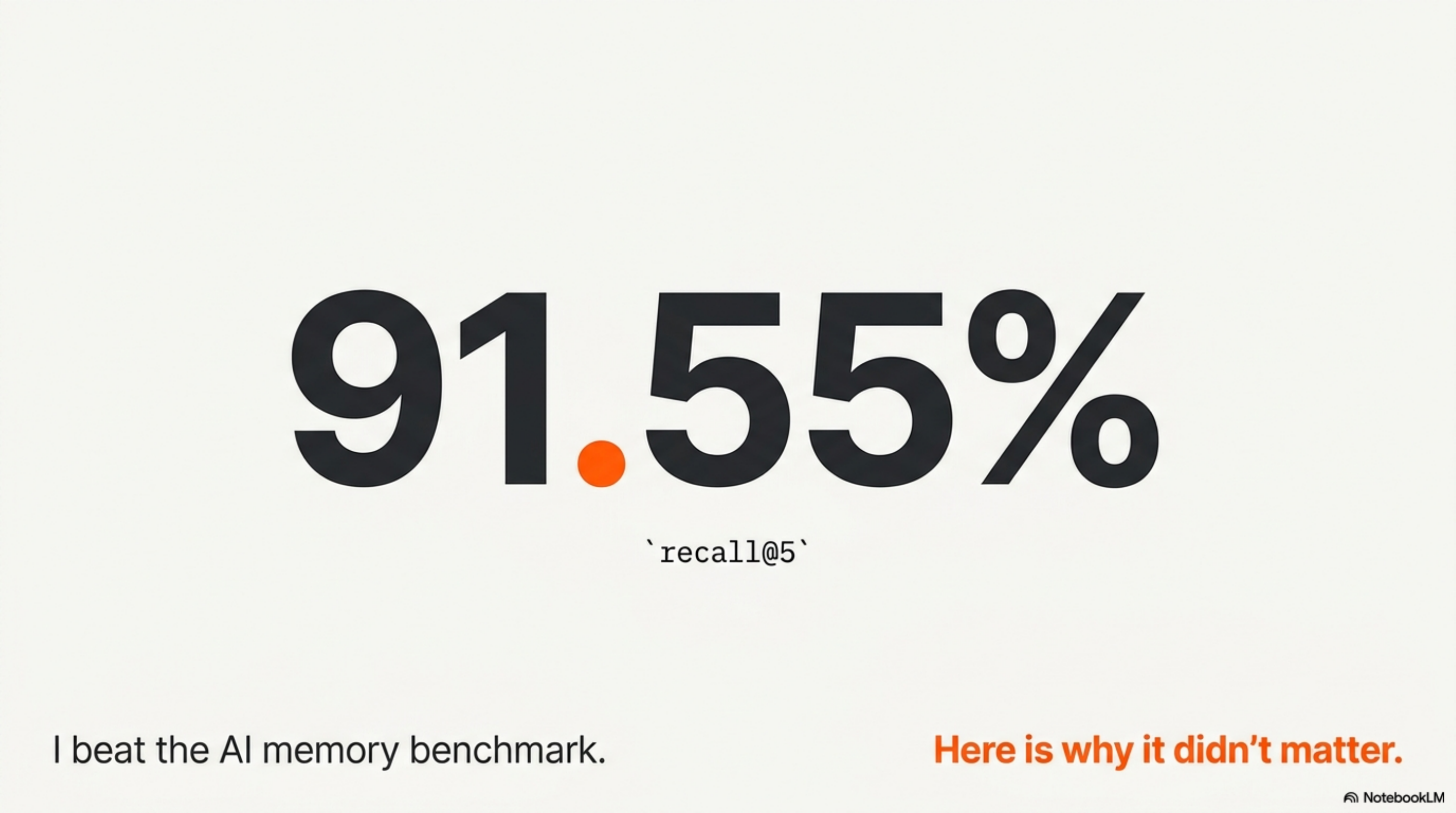
Two days ago I published Brain’s LongMemEval result: 408/500 = 81.60% end-to-end QA, with recall@5 = 91.55% over 470 non-abstention questions, using nothing but stdlib BM25 and a Claude Sonnet reader. That run beat the paper’s lexical baseline, sat in the middle of the public field, and gave me the cleanest number I am willing to defend.
It also gave me a problem I did not expect.
The number was real. The benchmark was the wrong shape.
The benchmark I needed was the one that would answer a different question: not “how does Brain rank against vendor leaderboards?” but “does Brain find the right document when I, the user of this corpus, ask the things I actually ask?” Generic memory benchmarks cannot answer that. They are not built to. So you build the one that can.
This post is about that pivot. It is post #4 in a series — after The 14K Token Debt, Benchmarking Long-Term AI Agent Memory, and the LongMemEval run itself. The earlier posts argued for the architecture and proved a credible baseline. This one argues for the benchmark you should build next, after the leaderboard number is out of your system.
The Number That Didn’t Matter
The clean LongMemEval result was honestly satisfying. 91.55% recall@5 is high. 81.60% end-to-end is in band with Supermemory’s gpt-4o row on the same dataset. The harness is real, runnable, resumable, and committed at bench/longmemeval/ in the Brain repo.
But sit with that result for a day, and it stops being prescriptive.
The number does not tell me whether Brain is good for me. Brain is supposed to find a decision I made three months ago about a Salesforce schema, the exact pg_dump flags I worked out for one client, the rejected prompt variant from a session I cannot otherwise locate. None of those questions exist in LongMemEval. They cannot. LongMemEval was built to compare memory systems against each other on a shared, neutral, synthetic substrate. It was not built to tell you whether your specific deployment helps you.
Two more things hardened the gap once I started looking:
-
The dataset is chat-shaped. LongMemEval evidence sessions are LLM-simulated dialogues — Llama-3-70B self-chats with human edits, padded with ShareGPT and UltraChat fillers. My corpus is not chat-shaped. It is markdown notes, code repos, browsing trails, distilled session artifacts, raw transcripts. The benchmark I just beat does not care.
-
The leaderboard is contaminated. Penfield Labs audited LoCoMo in November 2025 — the other dataset every memory vendor benchmarks on — and found 6.4% of the answer key wrong. The GPT-4o-mini judge accepted 62.81% of intentionally wrong answers. Mem0 misconfigured Zep and Letta in its arXiv paper; both vendors re-ran corrected configs and scored ~10% above Mem0’s own best. Zep’s own 84% LoCoMo claim was a numerator/denominator error, corrected to 58.44%, then re-defended at 75.14%.
This is the field every memory layer is competing on. I just paid the price of admission. I am no longer convinced admission was the right purchase.
I call this the Owned-Corpus Test: would my version of this system, on my data, answer the questions I actually ask? If a benchmark cannot answer that, it is a useful comparison — not your benchmark. LongMemEval is a useful comparison. It is not my benchmark.
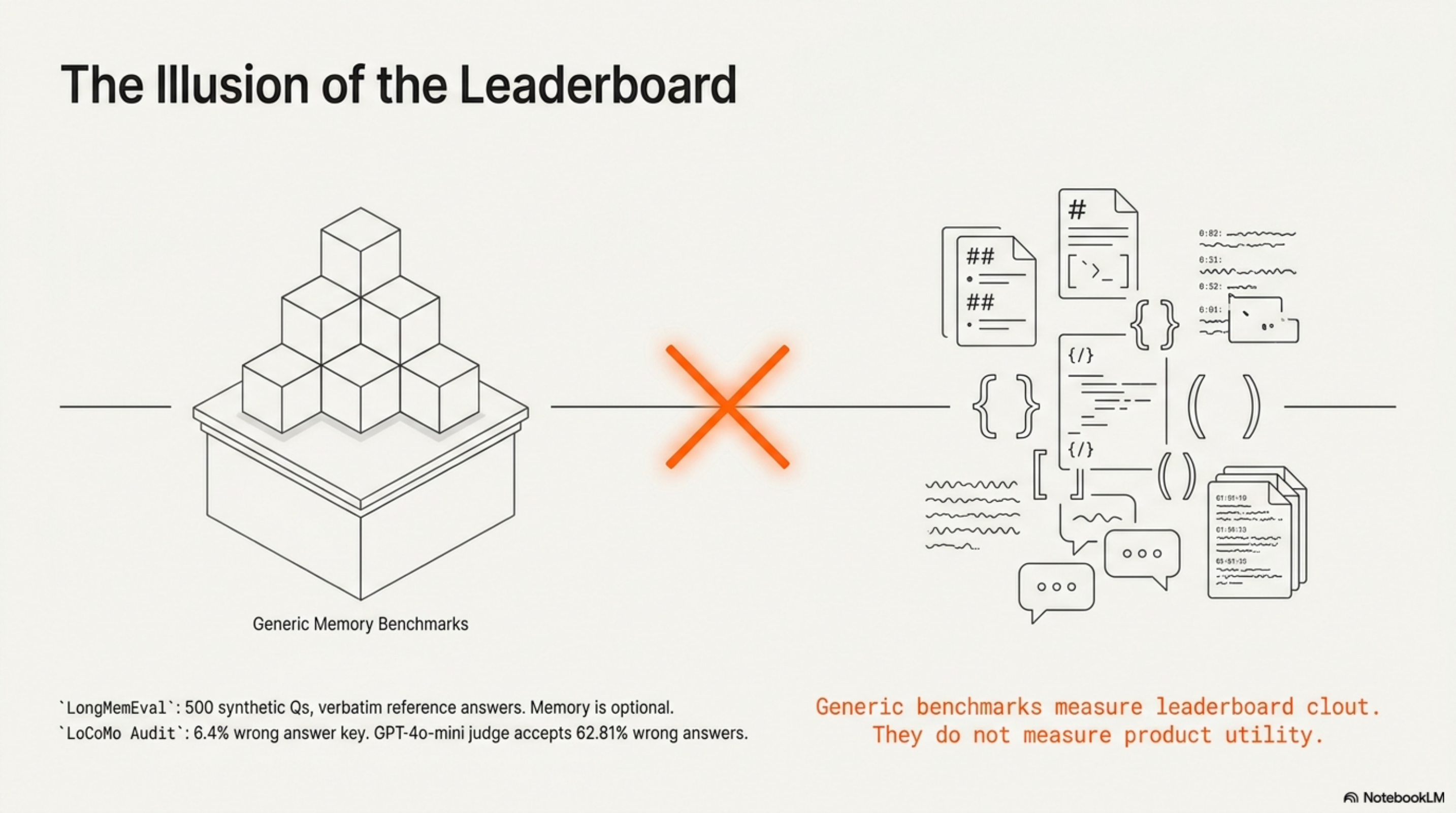
Why Generic Memory Benchmarks Won’t Tell You What You Need to Know
There is a structural reason this is not just about LongMemEval.
What the public benchmarks actually test
LongMemEval has 7 question types across 5 abilities, three variants (oracle / _s ~115k tokens / _m ~500 sessions), 500 questions total, evaluated with a GPT-4o judge against verbatim reference answers (paper). The haystack is fully synthetic. Filler sessions come from public dialogue datasets. Verbatim recall is the dominant strategy: MemPalace #314 documents that raw retrieval gets ~96% recall@5 on the dataset because the answers are literally in the haystack — you store everything, you find it.
LoCoMo is the other shared playing field. Ten very-long multi-session dialogues, persona-and-event grounded, multimodal. Same shape, longer history, the same audited cracks. Vendors love it because the conversations fit in modern context windows, which means the dataset is partially answerable without memory. Vectorize’s analysis of MemPalace’s benchmarks shows full-context GPT-4o (~73%) outscoring Mem0 (~68%) on LoCoMo.
Memory layers are benchmarking on tasks where memory is optional.
The Mastra observational-memory leaderboard for LongMemEval has Mastra at 94.87%, Vectorize/Hindsight at 91.40%, Emergence AI at 86.00%, Supermemory at 85.20%, Brain at 81.60%, RetainDB at 79.00%, Zep at 71.20%. Different reader models. Different judges. Some are research configurations the authors say are not reproducible. Some are vendor self-reports. Treating any of this as a tournament is sloppy. I said as much about my own row.
The shape mismatch is the killer point
Even if the leaderboard were clean, it would be the wrong shape for personal corpora.

I went through every question type in LongMemEval and tried to map it onto my corpus. The mapping breaks for at least four of seven. Single-session-assistant assumes the assistant said the answer; in a notes corpus there is no assistant. Single-session-preference assumes a preference is stated as a chat utterance; in a real workflow, preference is implicit in repeated behavior. Multi-session reasoning over chat is a different shape than synthesis across notes, code blame, and Slack threads. The benchmark is testing a chat-shaped world. I do not live in one.
I also looked at every alternative. LoCoMo, MemBench, MemoryAgentBench, MemoryBench, MEMTRACK. All chat or dialogue-shaped. The closest thing to a personal-corpus benchmark is EnronQA — 528K QA pairs over 150 historical email inboxes — and even that is academic, narrow, and leans on a corpus nobody currently uses.
No public benchmark evaluates retrieval over a user’s own markdown / notes / code corpus with the user’s own questions. The absence is the evidence.
The Voice vs Tool Gap

Here is what makes this awkward: the field already knows.
Hamel Husain has been the loudest voice on this for two years: “Generic metrics off-the-shelf… are generic enough to be useless for diagnosing your application’s failures.” His workflow is corpus → facts → questions those facts answer. Jason Liu’s writeup of Kelly Hong’s Chroma talk is titled, almost literally, stop trusting MTEB rankings. Shreya Shankar ships EvalGen and SPADE specifically because generic LLM-judges miss application-specific criteria. Jerry Liu ships Llama Datasets so you can benchmark on your own docs in a few lines.
Even the labs say it. Anthropic’s Contextual Retrieval cookbook ships a synthetic 100-sample evaluation set generated from your own docs as the canonical recipe. OpenAI’s RAG-evaluation cookbook recommends generate_question_context_pairs from LlamaIndex — same pattern.
So the message is loud. What about the tool? RAGAS, LlamaIndex, TruLens, Phoenix / Arize, DeepEval, Promptfoo, Patronus, Chroma’s generative-benchmarking — eight serious efforts.
RAGAS, LlamaIndex, DeepEval, and Chroma’s research repo all do something useful. Each ships a slice. But every one of them is shaped for enterprise document collections — pre-curated PDFs, well-defined domains, large doc sets where Q&A generation is expensive and rare. None of them is shaped for “point me at my notes folder, give me a benchmark in 10 minutes.” Nobody opinionatedly ships the personal-corpus version of the workflow.
Chroma’s W&B case study — the closest prior art — improved corpus alignment from 46% → 75% by generating queries directly from the corpus. That is the right idea. It is also a research repo, not a product. The closest individual example I could find is jasonjgarcia24/grounded, where one developer built a RAG over personal Gmail with a bespoke eval, no framework. That is the field’s tell. Practitioners are doing this by hand because the tooling does not yet exist.
I call this the Voice-Tool Gap: when thought leaders say it, when the labs ship cookbook recipes for it, when individual practitioners build it manually, but no opinionated tool exists for the most-asked use case — that is a gap, not a saturation.
The post does not solve the gap. Brain’s harness is a sketch, not a ship. But the gap is what makes the next experiment obvious.
Build It: A Five-Technique Recipe for Owned-Corpus Benchmarks

Here is the harness shape I would build today, given a corpus that looks like Brain’s: ~10k mixed docs (sessions, distilled summaries, raw articles, wiki concepts, browsing history), with both raw and synthesized layers, and a session-level usage log.
The recipe is five techniques, not one. Each compensates for the failure modes of the others.
1. RAGAS over your raw corpus

Start with RAGAS’s testset generator over your raw docs. RAGAS turns a chunk into seed questions, then evolves them via Evol-Instruct-style operators (simple, reasoning, multi_context, conditioning) to break out of “the answer is the chunk.”
Failure mode: lexical leakage. Generated questions can parrot the chunk verbatim, which inflates BM25 scores. Filter with an LLM-judge “would a human ask this exact question?” pass.
2. Reverse-direction grounding (synthesized → source)
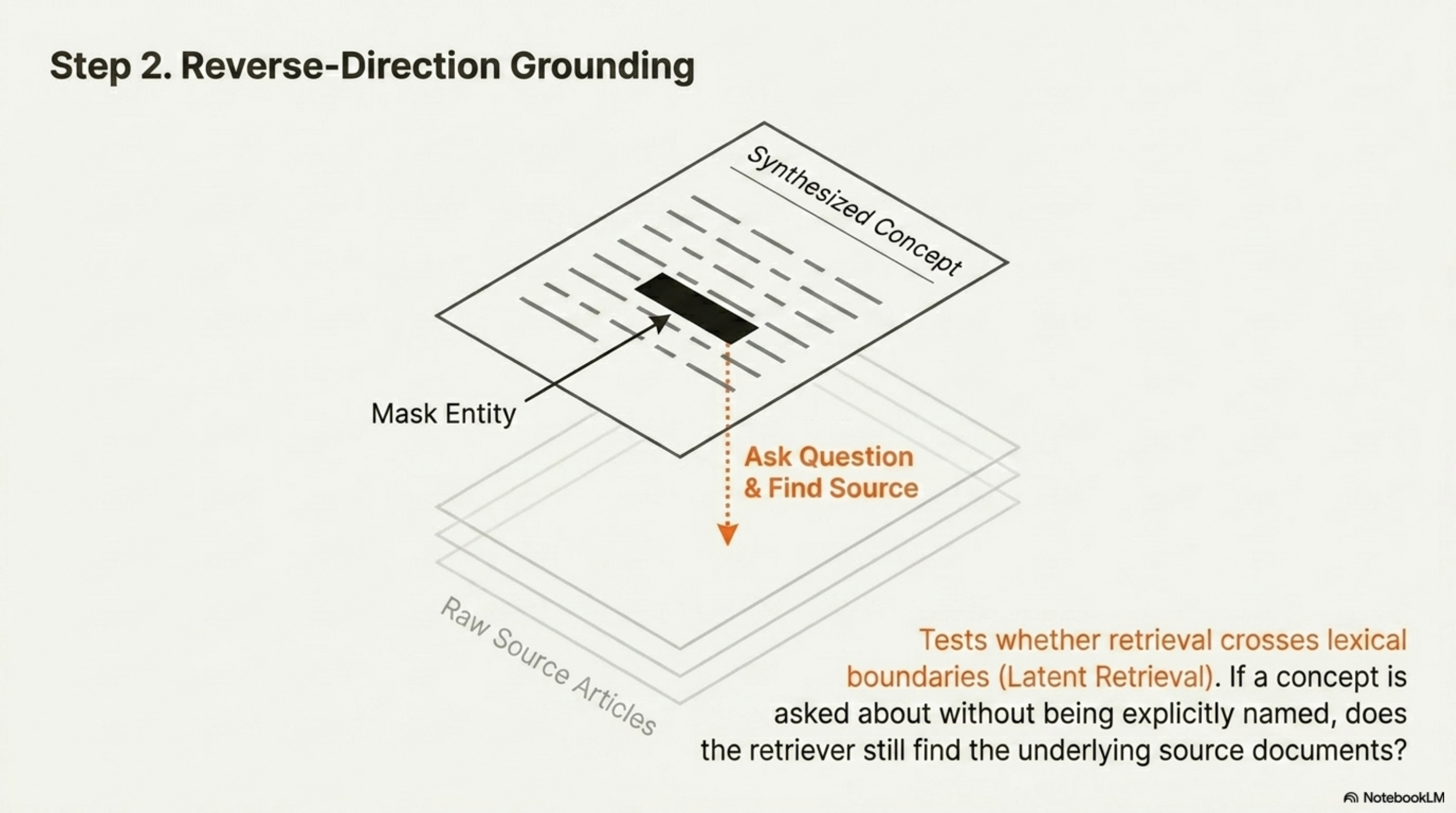
This is the technique that exploits the structure of a personal corpus: you have synthesized concept pages (kb-wiki) and the source articles they were synthesized from (kb-raw). Take a wiki page about a concept, mask the entity name, and ask an LLM to write a question about the concept without naming it. Then test whether retrieval finds the underlying source articles. The metric is kb-raw recall@k.
This is closest in spirit to ORQA’s latent retrieval — the “real test” of semantic search. It is the eval you cannot do on a generic corpus, and it is the eval that tells you whether your retrieval crosses lexical boundaries.
3. Hindsight queries from real session logs
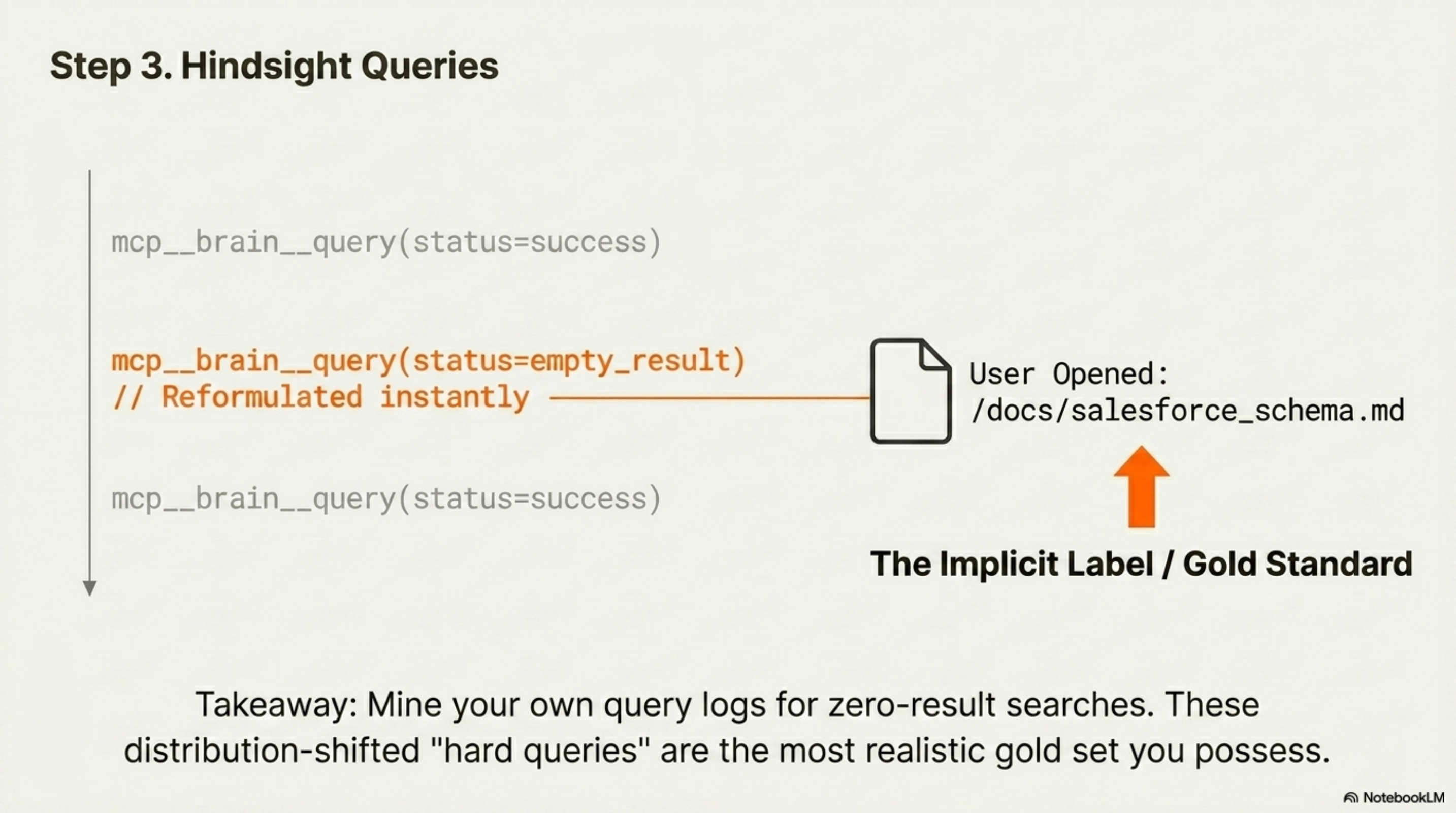
Mine real query logs. For Brain, this means scraping mcp__brain__query calls from every Claude Code session where the result set was empty or the user reformulated the query immediately. Each one is a gold “hard query” — distribution-shifted by definition.
Joachims’s clickthrough-as-implicit-feedback is the academic anchor; Microsoft Xbox’s search relevance work and Dropbox Dash’s labeling pipeline are the production analogues. For a personal corpus, you instrument the retriever and treat the doc the user actually opened next as the gold label. Cold start is real (you need usage logs to mine), but for any system that has been running a few months, this is your most realistic gold set.
4. Distractor injection
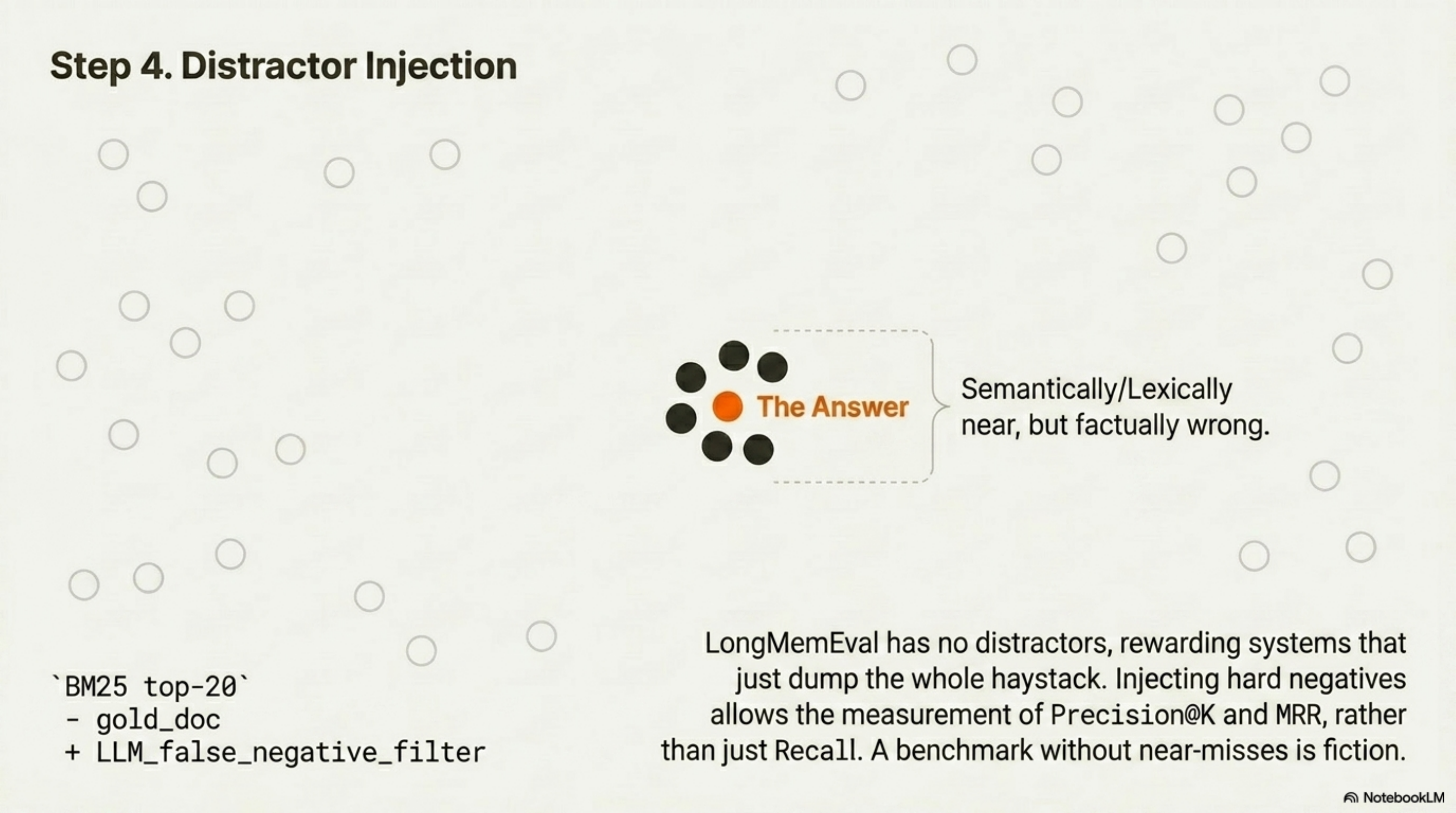
Take each (query, gold doc) pair and add hard negatives — semantically near, lexically near, but wrong. Standard recipe: BM25 top-20 minus gold, then LLM-filter false negatives (RLHN, 2025). Now you can measure precision@k and MRR, not just recall@k.
This is the single biggest fix to the LongMemEval failure mode. LongMemEval rewards “store everything” because there are no distractors that look like answers. Personal corpora are full of near-misses. If your eval does not include them, your number is fiction.
5. Calibration via small hand-graded set

Hand-grade 50 examples. Compute Cohen’s kappa between your hand labels and the LLM-judge labels. Refuse to trust bulk metrics until kappa ≥ 0.6 (Langfuse’s calibration guide is the cleanest writeup). 50 is the floor for a stable agreement metric; less and your kappa is noise.
You only do this once per judge prompt revision. It is cheap, and it is the only way to defend “we used an LLM judge.”
Putting it together

Total: 280 questions, four metrics, one calibration. About two days of work for someone with a working corpus and a working retriever. Skip step 3 if you do not yet have query volume; everything else is bootstrappable.
The harness shape, mirrored from bench/longmemeval/: a fetch.py to mine the corpus into chunks; generate.py for RAGAS testset over kb-raw; reverse.py for kb-wiki → kb-raw masked questions; replay.py for zero-result query mining from session logs; distractors.py for BM25 top-k minus gold with an LLM filter; calibrate.py for the 50-sample hand-grade kappa gate; run.py for retrieval and reader with scrub-on-restart resume; score.py with tri-state labels and oracle ceilings; and report.py for the per-collection × per-question-type breakdown with CIs.
This is the next thing I am going to build.
What Will Go Wrong (And How the Field Thinks About It)

I built the LongMemEval port and hit five real bugs along the way: a 12K context cap that silently truncated long haystacks, a coupled-failure anti-pattern where reader exceptions threw away retrieval logs, judge rate-limit errors recorded as label=False, cross-question leakage from shared scratch collections, and eval QAs getting re-indexed into Brain’s production corpus on the next sync. Each has a clean field-term framing. Listing them honestly is the part of the post I owe the reader, because every one will catch the next person to build a personal-corpus benchmark.
There are four more pitfalls the field knows about that I had not yet hit:
Judge variance and bias. GPT-4-class judges hit ~80% human agreement only after controlling position, verbosity, and self-enhancement bias (Zheng et al., MT-Bench). Position bias is non-random — running both orderings is required, not optional (Shi et al., 2024). For a credible owned-corpus eval, run both orderings and take majority of three samples; confidence-improved self-consistency cuts the sample budget by ~40%.
Retrieval ≠ reader. Always report both. The single biggest mistake in vendor reporting is publishing recall@k as if it were end-to-end accuracy. Brain’s Evidence Conversion Gap — recall@5 = 91.55%, QA = 81.60%, gap = 9.95 points — is a generalizable framing. Always report retrieval and answer metrics separately, and put oracle-retrieval and oracle-reader ceilings on each so you can localize regressions (Hamel’s LLM-as-judge guide covers this cleanly).
Goodhart and overfitting your eval. The moment you start tuning to your own benchmark, the metric measures tuning effort. Sohl-Dickstein on strong Goodhart is the canonical reference; the Chatbot Arena gaming case is the public demonstration. Hold out 20–30% of your questions until milestone gates. Freeze v1 of your eval set when the corpus changes meaningfully; v2 reports both splits.
Statistical power. Cameron Wolfe’s stats-for-LLM-evals primer gives the rule of thumb: 25–50 questions detect a 10% gap, 100–200 detect 5%, 2500–5000 detect 1% at 80% power. LLM outputs are correlated, which means effective N is lower than nominal. If your benchmark has 50 questions and you are claiming a 3% improvement, you have not measured anything yet.
Where This Breaks
I owe the same honesty about this thesis that I owed about the LongMemEval result.
| Limitation | Why it matters | What I would do before claiming more |
|---|---|---|
| The owned-corpus benchmark cannot be cross-system compared | LongMemEval at least lets you compare Brain to Mastra | Keep running LongMemEval as a comparison signal alongside the owned-corpus benchmark; do not abandon either |
| Ground-truth Q&A from your own corpus has its own biases | The generator model leaks vocabulary; reverse-grounding can anchor on hallucinated wiki claims; mined queries are survivorship-biased | Hybrid generation across multiple models; manual review of the wiki-side anchors; explicit “no result” gold for mined queries |
| LLM-as-judge is the floor, not the ceiling | Your judge has the same blind spots as your reader | Use a different model family for judge vs. reader; calibrate against 50 hand-graded examples; report kappa publicly |
| Personal corpus eval is high-variance with one rater | One person’s labels are noisy compared to inter-rater agreement | Hand-grade with at least one collaborator before publishing; or compare to an independent LLM-judge of a different family |
| Storing your eval set securely | Personal data leaks if the eval corpus is open-sourced naively | Keep eval data in a private collection; canary tokens prevent re-ingest; never commit ground-truth to a public repo |
This is a methodology argument, not a finished benchmark. The work is the next post.
What I Am Actually Saying

The argument is narrower than “stop running LongMemEval.”
LongMemEval is useful for cross-vendor comparison. It exposed a real weakness in Brain’s multi-session synthesis. It will continue to be a credibility signal for vendor leaderboards. Generic memory benchmarks are a weak prior, not zero signal.
The argument is sharper than that:
For a deployment that exists to help one user (or one team) with one corpus, the leaderboard number is decoration. The prescriptive number — the one that tells you whether to ship — comes from a benchmark you build on your own corpus, with questions you actually ask, on the failure modes that actually bite you. The leaderboard cannot do that work. The labs already say so. The frameworks ship the pieces. The field has the language. What is missing is the opinionated tool that turns a notes folder + a retriever into a benchmark in ten minutes.
If someone builds that tool, half the memory-layer market will use it. Vendor leaderboards will become a sanity check, not a North Star. The conversation will move from “we hit 94.87% on LongMemEval” to “the user reports an 8-point lift in retrieval-and-answer correctness against their own questions, calibrated against 50 hand-graded examples, kappa 0.71.”
That is a more useful conversation. It is also a harder one — because the benchmark is yours, not ours.
I am building the tool for Brain. The harness from the LongMemEval port is the spine; the techniques in section 5 are the layers. The next post in this series will be the result.
The closing question is simple: does anyone else want to build the public version of this? RAGAS, LlamaIndex, Chroma, DeepEval, Phoenix all ship the substrate. None of them ships the opinionated personal-corpus harness. Whoever does will set the next standard for memory-layer evaluation.
I will read your benchmark before I read your leaderboard.

Links Worth Following
| Topic | Link | Why |
|---|---|---|
| LongMemEval paper | arXiv:2410.10813 | Defines the benchmark and the long-term-memory task shape |
| LoCoMo audit | Penfield Labs / dev.to | Documents 6.4% wrong answers in the LoCoMo answer key and 62.81% wrong-answer acceptance |
| Mem0 vs Letta methodology dispute | Letta blog | Concrete example of vendor benchmark misconfiguration |
| Zep LoCoMo correction | Zep Papers Issue #5 | The 84% → 58.44% → 75.14% saga; cautionary tale |
| Mastra observational-memory leaderboard | mastra.ai/research | The most-cited public LongMemEval scoreboard |
| RAGAS testset generation | RAGAS docs | The closest-to-product Q&A-from-corpus tool |
| LlamaIndex Llama Datasets | LlamaIndex blog | The other framework path; closest to “benchmark in a few lines” |
| Anthropic Contextual Retrieval | platform.claude.com cookbook | Anthropic’s official “synthetic eval set from your own docs” recipe |
| OpenAI RAG eval cookbook | cookbook.openai.com | The OpenAI version of the same recipe |
| Hamel Husain on RAG evals | hamel.dev | Sharpest “generic metrics are useless” argument I have read |
| Jason Liu on MTEB | jxnl.co | Domain-specific eval as the only signal that survives |
| Chroma generative-benchmarking | research.trychroma.com | Closest existing prior art for owned-corpus generation |
| MT-Bench / LLM-as-judge | Zheng et al. | Judge bias controls; the position-bias and self-preference findings |
| Stats for LLM evals | Cameron Wolfe | The N-vs-effect-size table every benchmark builder needs |
This is post #4 in a series on agentic AI memory infrastructure. Earlier posts: The 14K Token Debt, Benchmarking Long-Term AI Agent Memory, Brain on LongMemEval: 81.6%. The next post in the series will be the owned-corpus benchmark itself, when it ships.