590 Sessions Later
A year ago I wrote about the 14K token debt — the idea that your system prompt is the most important architectural decision in agentic AI. That post argued for building a temporal knowledge graph: index your Claude Code sessions, feed the agent its own past, and compound returns across sessions.
I’ve been running that system in production for six months. The question I couldn’t answer back then: does it actually work?
So I ran the experiment. 14 queries, 28 runs, two conditions. This post documents the system, the methodology, the results, and the one finding I didn’t expect — that an agent doing more work can cost less, if the work is structured right.
The System
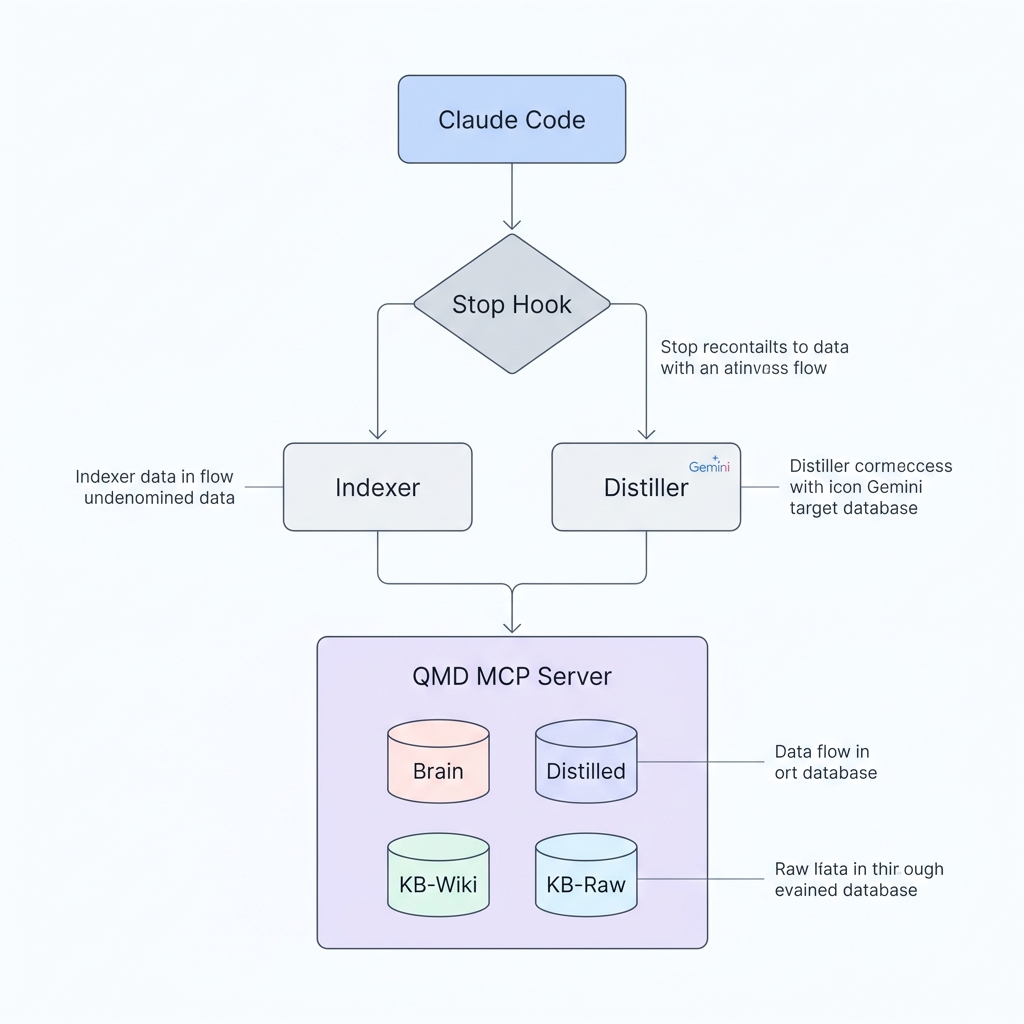
The system is called Brain MCP. It is a memory layer that sits between Claude Code and QMD, Tobi Lutke’s MCP-native search server. QMD provides BM25, vector, and hypothetical document search over markdown collections via the Model Context Protocol. Brain MCP adds four things on top:
- A session indexer that parses Claude Code’s JSONL transcripts into structured markdown with frontmatter, conversation turns, tool logs, and reasoning traces.
- An LLM distillation pipeline that compresses each session into a dense knowledge artifact — goals, decisions, rejected approaches, concept tags — using Gemini 2.5 Flash.
- An automated sync loop that triggers on every session end, keeping the index current without any human intervention.
- A self-optimizing search strategy that mutates its own parameters and measures the results against a deterministic scoring function.
The architecture:
Claude Code Session
|
v
[Stop Hook] ─────────────────────────────+
| |
v v
brain.py index qmd update
(JSONL → sessions/*.md) (BM25 reindex)
|
v
[cron every 2h]
|
v
brain.py distill
(Gemini 2.5 Flash)
|
v
distilled/*.md ┌──────────────────────┐
(goals, decisions, tags) │ QMD MCP Server │
| │ │
v │ lex: BM25 keyword │
qmd embed │ vec: semantic │
(vector embeddings) │ hyde: hypothetical │
| │ │
+────────────────────────►│ 4 collections: │
│ brain (590 docs)│
│ distilled (395 docs)│
│ kb-wiki (211 docs)│
│ kb-raw (526 docs)│
└──────────┬────────────┘
│
v
Claude Code queries
its own pastProduction stats as of April 2026: 597 sessions indexed. 395 distilled. 1,709 total searchable documents across four collections. The Stop hook fires in under two seconds. The cron job runs every two hours.
The Four Collections
Each collection serves a different retrieval purpose. This isn’t arbitrary — it’s the result of six months of iterating on what the agent actually needs at query time.
| Collection | Docs | What’s in it | When it helps |
|---|---|---|---|
| brain | 590 | Raw session transcripts — every tool call, file read, decision, correction | When you need verbatim recall: “what exact command did I run?“ |
| distilled | 395 | LLM-compressed summaries — goals, key decisions, rejected approaches, concept tags | When you need semantic recall: “what did I decide about auth?“ |
| kb-wiki | 211 | Synthesized concept pages, comparison tables, entity summaries | When you need general knowledge: “how does BM25 work?“ |
| kb-raw | 526 | Raw source articles, transcripts, documentation | When you need primary sources: the original article about RAG architectures |
The insight behind having both brain and distilled is that they fail in complementary ways. Raw transcripts are noisy but lossless — you can grep for the exact error message you saw three months ago. Distilled artifacts are clean but lossy — the LLM may have dropped a detail that turns out to matter. Together, they cover more ground than either alone.
Three Search Modes
QMD exposes three search modes, each suited to different query types:
- lex (BM25): Classical keyword matching with TF-IDF weighting. Fast, exact, no embedding required. Best for: specific error messages, CLI commands, file paths, proper nouns.
- vec (semantic): Dense vector similarity over document embeddings. Best for: conceptual queries where the exact terms don’t appear in the document (“authorization failures” matches a session about “JWT token rejection”).
- hyde (hypothetical document): You write a short paragraph describing what the answer looks like. The engine embeds that paragraph and finds documents similar to it. Best for: open-ended questions where you know the shape of the answer but not where it lives.
A single query can combine all three. The search_strategy.yaml controls the order — the first sub-query gets 2x weight during reranking:
queries:
sub_query_order: [lex, vec, hyde]
hyde_template: >
The answer to the question "{query}" in the context of AI agents,
LLM systems, autonomous research loops, and knowledge base design is:The Indexer
The session indexer (brain.py) is 614 lines of Python with no dependencies beyond the standard library (plus google-genai for distillation). It does two things: parse JSONL transcripts into markdown, and distill them via LLM.
Parsing: JSONL to Markdown
Every Claude Code session produces a JSONL file where each line is a JSON object with a type field: system, user, assistant. Assistant messages contain content blocks — text, thinking, and tool_use. The parser extracts all three:
EXTRACT_INPUT_TOOLS = {"Read", "Edit", "Write", "Glob", "Grep",
"Bash", "WebSearch", "WebFetch"}
def extract_tool_summary(block: dict) -> str | None:
"""Return a one-line summary of a tool_use block."""
name = block.get("name", "")
inp = block.get("input", {})
if name == "Bash":
cmd = inp.get("command", "").strip()
if cmd:
return f"Bash: {cmd[:120]}"
elif name in ("Read", "Edit", "Write", "Glob", "Grep"):
path = (inp.get("file_path") or inp.get("pattern")
or inp.get("path") or "")
if path:
return f"{name}: {path}"
...The output is a markdown file with YAML frontmatter (for QMD indexing) and three sections: Conversation, Tools Used, and Reasoning. Each session gets one file in ~/.brain/sessions/:
---
session_id: 02b3c2d7-22e2-4f22-b270-bb14c60e1c87
slug: rosy-sprouting-sprout
date: 2026-04-02
project: ~/Projects/udacity-reviews-hq/projects/travel-agent/tmp
branch: master
---
## Conversation
**User**: Can you diagnose when I enter this command, `gemini -yolo`?
It takes like 6-7 good seconds to boot up...
**Assistant**: Found the main culprit. There are two issues...
## Tools Used
- Read: ~/.gemini/settings.json
- Bash: strace -e trace=network gemini --yolo 2>&1 | head -30
- Edit: ~/.gemini/settings.json
## Reasoning
> The user reports 6-7 second startup delay. Let me check if there's
> a blocking network call or file I/O issue in the gemini CLI...The --new flag makes indexing incremental — it only processes JSONL files whose modification time is newer than the corresponding .md file. The --queue flag appends newly indexed session stems to pending_distill.txt for the cron job to pick up later.
The Stop Hook
The key infrastructure is a Claude Code Stop hook that fires after every session ends:
{
"hooks": {
"Stop": [{
"matcher": "",
"hooks": [{
"type": "command",
"command": "python3 ~/.brain/brain.py index --new --queue >> ~/.brain/index.log 2>&1 && qmd update >> ~/.brain/index.log 2>&1"
}]
}]
}
}This runs synchronously before the session fully closes. Two operations: index --new --queue (parse any new JSONL files, enqueue for distillation) and qmd update (rebuild the BM25 index). Total latency: under two seconds. The user doesn’t notice.
The heavy work — LLM distillation and vector embedding — happens asynchronously via a cron job every two hours:
#!/usr/bin/env bash
# cron_sync.sh — runs every 2 hours
# 1. Catch any sessions missed by the Stop hook
python3 ~/.brain/brain.py index --new --queue
# 2. Drain distillation queue via Gemini
python3 ~/.brain/brain.py distill --from-pending
# 3. BM25 reindex (picks up new distilled/ files)
qmd update
# 4. Refresh vector embeddings (~17s per batch)
qmd embedThis two-tier architecture — fast synchronous indexing on every session, slow asynchronous distillation on a cron — means the BM25 index is always current (within seconds) while the semantic index catches up within two hours. In practice, this is good enough: by the time I need to semantically search a session, the cron has already processed it.
The Distillation Pipeline
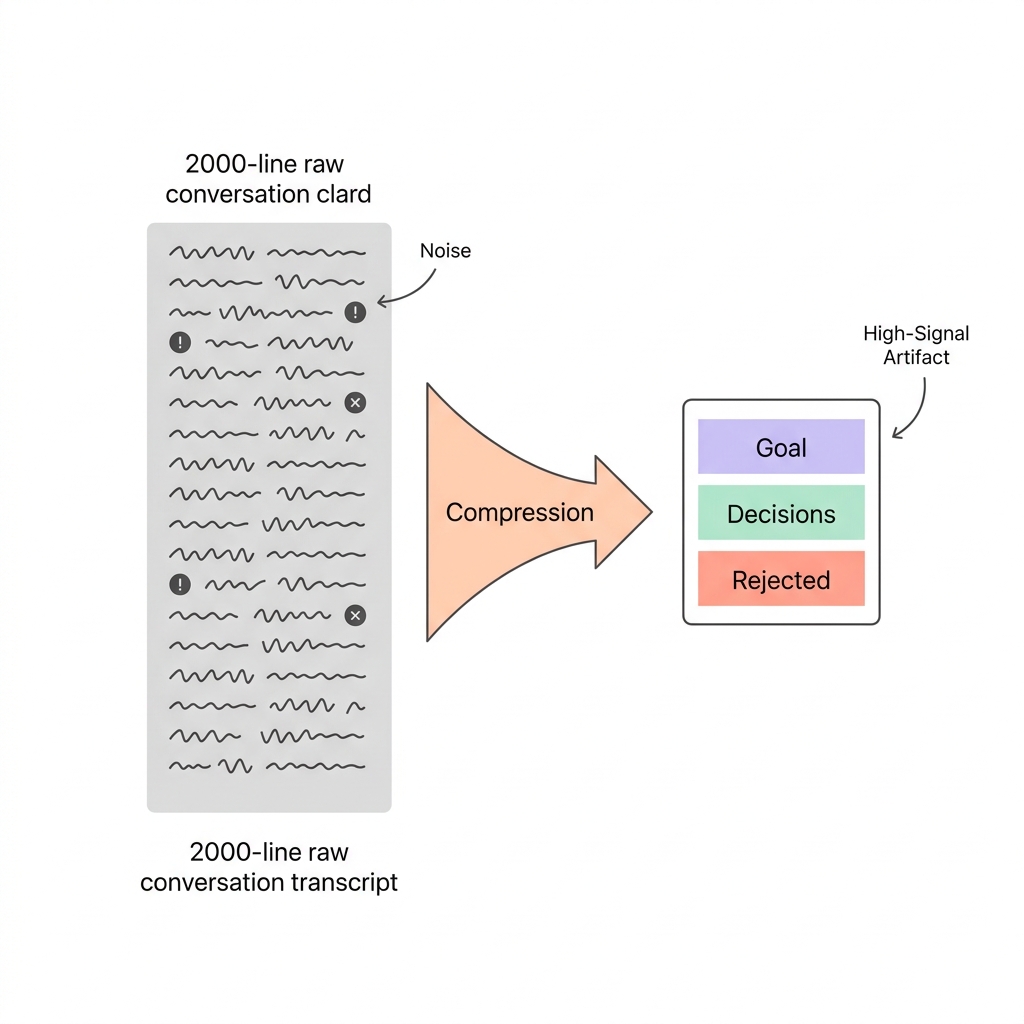
This is the layer that makes the system more than a glorified grep. Raw session transcripts are 50-200 lines of conversation noise — tool calls, error messages, tangential explorations, corrections. The distillation pipeline compresses each session into a ~30-line structured artifact that captures what actually matters.
What Distillation Produces
Here’s a real example. The raw session is a 60-line transcript about diagnosing a 6-7 second startup delay in the Gemini CLI. Here’s what the distiller produces:
---
session_id: 02b3c2d7-22e2-4f22-b270-bb14c60e1c87
date: 2026-04-02
project: ~/Projects/udacity-reviews-hq/projects/travel-agent/tmp
distilled: true
distilled_at: 2026-04-06
prompt_version: v1-d68727f6c6f4
confidence: High
---
## Goal
Diagnose and resolve a 6-7 second startup delay in the `gemini -yolo` command.
## What Happened
Initial diagnosis revealed a blocking IDE extension connection timeout
caused by `ide.enabled: true` in `~/.gemini/settings.json`. After
disabling IDE integration, a new 12.5s delay (10s I/O wait) was traced
to a 730MB `~/.gemini/tmp/` directory with 1,298 session checkpoint files.
## Key Decisions
- Disabled IDE integration — not using Windsurf features from terminal
- Identified two separate bottlenecks (network timeout + I/O wait)
## What Was Rejected
- Did not immediately disable session retention without understanding it
## Technologies
gemini, Windsurf, Node.js, Claude Code
## Concepts
CLI startup performance, IDE integration, connection timeout, I/O wait,
session retention, headless execution
## Tags
gemini cli, startup performance, ide integration, connection timeout,
session retention, performance optimization, troubleshootingThe raw transcript has the full diagnostic conversation — the back-and-forth about what IDE integration does, the strace commands, the file size checks. The distilled version has the intelligence: what was the goal, what was decided, what was rejected, and what concepts were involved.
The Distillation Prompt
The prompt is carefully designed to prevent the most common failure mode: LLM invention. The distiller must extract only what is explicitly stated, never infer or fabricate:
DISTILL_PROMPT = """You are a technical knowledge distiller.
Given a Claude Code conversation, extract a structured knowledge artifact.
Output this exact structure:
---
session_id: {session_id}
date: {date}
project: {project}
...
---
## Goal
[One sentence. If purely exploratory with no clear goal, say so.]
## What Happened
[3-5 sentences. Past tense. Include outcome.]
## Key Decisions
[2-5 bullet points. Omit entire section if no decisions were made.]
## What Was Rejected
[0-3 bullet points. Omit if none -- do NOT invent rejections.]
...
Rules:
- Only extract what is EXPLICITLY stated. Never invent.
- Keep Goal to one sentence maximum.
- If session is a narrow sub-agent task, describe that task accurately.
"""The prompt version is tracked via a hash (v1-d68727f6c6f4). When the prompt changes, the --new flag detects stale distillations by checking the prompt_version field in existing files and re-queues them.
Cost and Throughput
Distillation runs on Gemini 2.5 Flash. I evaluated four options before settling on this:
| Model | Cost per 394 sessions | Speed | Tradeoff |
|---|---|---|---|
| Gemini 2.5 Flash (batch) | $0.38 | ~1 hour | Best price/quality |
| Qwen 3.5 Plus (batch) | $0.27 | ~1 hour | Cheapest, Alibaba account needed |
| Kimi K2.5 | $0.72 | ~5 min | No batch discount |
| Gemma 4 12B (local) | $0.00 | ~65 min | Zero cost, M1 Pro 40 tok/s |
At $0.38 for the initial 394-session backfill and ~$0.001/day ongoing, the cost is effectively zero. The session text is truncated to 8,000 characters before being sent to the LLM — enough to capture the essential decisions without hitting rate limits on long sessions.
Rate limiting is handled with exponential backoff:
for attempt in range(3):
try:
response = client.models.generate_content(
model="gemini-2.5-flash", contents=prompt
)
return response.text.strip()
except Exception as e:
if "429" in str(e) or "RESOURCE_EXHAUSTED" in str(e):
wait = 60 * (2 ** attempt) # 60s, 120s, 240s
time.sleep(wait)The Experiment
Design
I took 14 knowledge retrieval queries spanning five categories:
Operational recall (3 queries): Questions about specific past decisions.
- “What decisions were made about the OpenClaw sandbox bind mount configuration?”
- “How was the brain MCP CLI designed and what was rejected?”
- “What is the current state of the OpenClaw artifact classification pipeline?”
Architecture (3 queries): System design and understanding.
- “How do autonomous LLM agents use tools and manage context across turns?”
- “What is the architecture of a RAG system and where does retrieval quality break down?”
- “How should a knowledge base be structured for LLM retrieval and synthesis?”
Research concepts (3 queries): Conceptual knowledge retrieval.
- “What are the tradeoffs between BM25 keyword search and semantic vector search?”
- “How does the Karpathy autoresearch loop pattern work?”
- “What techniques improve LLM reasoning quality on complex multi-step tasks?”
Cross-project debugging (3 queries): Lessons learned across projects.
- “Why do multi-agent systems fail to coordinate?”
- “What deployment mistakes caused the most debugging sessions?”
- “How was the Jules API integration implemented?”
Active project context (2 queries): Current state awareness.
- “What is the current goal of the Google Ads autoresearcher project?”
- “What LLM agent frameworks have been used across projects?”
These 14 queries were originally created for the autoresearch loop’s test suite — they weren’t cherry-picked for the benchmark. They span all four collections and represent the kinds of questions I actually ask the brain in production.
Conditions
Two conditions, run sequentially on the same machine:
Vanilla: Claude Code with brain MCP tools blocked via --disallowedTools mcp__brain__query,mcp__brain__get,mcp__brain__multi_get,mcp__brain__status. The agent can only use Grep, Glob, Read, and Bash to search ~/.brain/ files manually. It has access to the same data — just not the structured retrieval tools.
Brain MCP: Claude Code with full access to QMD brain MCP tools. The agent can issue multi-mode search queries (lex/vec/hyde) across all four collections and retrieve documents by path.
Both conditions use:
- Claude Sonnet 4 (
claude-sonnet-4-6) - Identical system prompt: “You are a knowledge retrieval agent. Answer the user’s question using the tools available to you. Search thoroughly, then provide a concise, well-sourced answer.”
- Pipe mode (
claude -p --output-format json) for structured metrics - 10-minute timeout per query
- No session persistence (
--no-session-persistence) - Bypass permissions (
--permission-mode bypassPermissions)
Measurement
The benchmark harness (benchmark_harness.py) captures metrics from Claude Code’s JSON output:
usage = data.get("usage", {})
inp_tok = usage.get("input_tokens", 0)
out_tok = usage.get("output_tokens", 0)
cache_read = usage.get("cache_read_input_tokens", 0)
cache_create = usage.get("cache_creation_input_tokens", 0)
# Effective tokens = everything the model actually processed
effective_tokens = inp_tok + out_tok + cache_read + cache_createMetrics per experiment: effective tokens processed, output tokens generated, cache read/create tokens, agentic turns, API latency (server-side), wall-clock time, cost in USD, answer length in characters.
The harness strips ANTHROPIC_API_KEY from the environment to ensure Claude Code uses OAuth rather than a stale API key:
env = {k: v for k, v in os.environ.items() if k != "ANTHROPIC_API_KEY"}28 experiments total: 14 queries x 2 conditions. Vanilla runs first, then Brain MCP. This ordering matters — I’ll address the bias it introduces in the limitations section.
The Results
Aggregate
| Metric | Vanilla | Brain MCP | |
|---|---|---|---|
| Total cost | $5.64 | $3.18 | 1.8x cheaper |
| Wall-clock | 39.5 min | 21.9 min | 1.8x faster |
| API latency | 1,621s | 951s | 1.7x faster |
| Output tokens | 22,537 | 46,355 | 2.1x more generated |
| Answer length | 48,054 chars | 56,129 chars | 17% longer answers |
| Tokens processed | 1.1M | 3.5M | 3.2x more throughput |
| Agentic turns | 57 | 185 | 3.2x more turns |
| Failures | 1 timeout | 0 | 100% completion |
Brain MCP won on cost for 12 of 14 queries (86%). Won on speed for 12 of 14 (86%).
Per-Query Breakdown
| # | Query | V Cost | B Cost | Savings | V Wall | B Wall | Speedup |
|---|---|---|---|---|---|---|---|
| 1 | OpenClaw sandbox decisions | $0.34 | $0.12 | 2.7x | 113s | 52s | 2.2x |
| 2 | Brain CLI design + rejections | $0.54 | $0.23 | 2.3x | 402s | 97s | 4.1x |
| 3 | OpenClaw artifact classification | TIMEOUT | $0.17 | — | 300s | 89s | 3.4x |
| 4 | Autonomous LLM agents + tools | $0.52 | $0.20 | 2.6x | 166s | 111s | 1.5x |
| 5 | RAG architecture + quality | $0.38 | $0.16 | 2.3x | 111s | 77s | 1.4x |
| 6 | Knowledge base for LLM retrieval | $0.41 | $0.19 | 2.1x | 148s | 97s | 1.5x |
| 7 | BM25 vs semantic search | $0.37 | $0.14 | 2.8x | 119s | 60s | 2.0x |
| 8 | Karpathy autoresearch loop | $0.23 | $0.28 | 0.8x | 72s | 82s | 0.9x |
| 9 | LLM reasoning techniques | $0.43 | $0.24 | 1.8x | 146s | 134s | 1.1x |
| 10 | Multi-agent coordination | $0.52 | $0.42 | 1.2x | 245s | 161s | 1.5x |
| 11 | Deployment debugging | $0.72 | $0.21 | 3.5x | 180s | 89s | 2.0x |
| 12 | Jules API integration | $0.63 | $0.19 | 3.4x | 159s | 66s | 2.4x |
| 13 | Google Ads autoresearcher | $0.28 | $0.24 | 1.2x | 90s | 90s | 1.0x |
| 14 | LLM agent frameworks survey | $0.28 | $0.40 | 0.7x | 119s | 109s | 1.1x |
The biggest wins cluster around targeted recall queries — questions with a specific right answer that lives in a specific document. Query 11 (deployment debugging) shows the pattern most clearly: vanilla Claude Code spent $0.72 and 180 seconds doing broad grep scans across ~/.brain/sessions/, reading full files, getting noise. Brain MCP spent $0.21 and 89 seconds making targeted queries, reading the top-ranked results, and synthesizing.
Query 2 (brain CLI design) is the most dramatic speedup: 4.1x faster. Vanilla took 402 seconds — over six minutes of file searching — while Brain MCP needed 97 seconds. The vanilla agent made 5 turns of broad file reads. Brain MCP made 13 turns of targeted retrieval, each turn cheap because the system prompt was already cached.
Query 3 (OpenClaw artifact classification) is the only vanilla timeout. The agent spent its full 5-minute budget on grep scans without finding the right session files. Brain MCP answered the same query in 89 seconds with 10 targeted turns.
The Counterintuitive Finding: Why More Work Costs Less
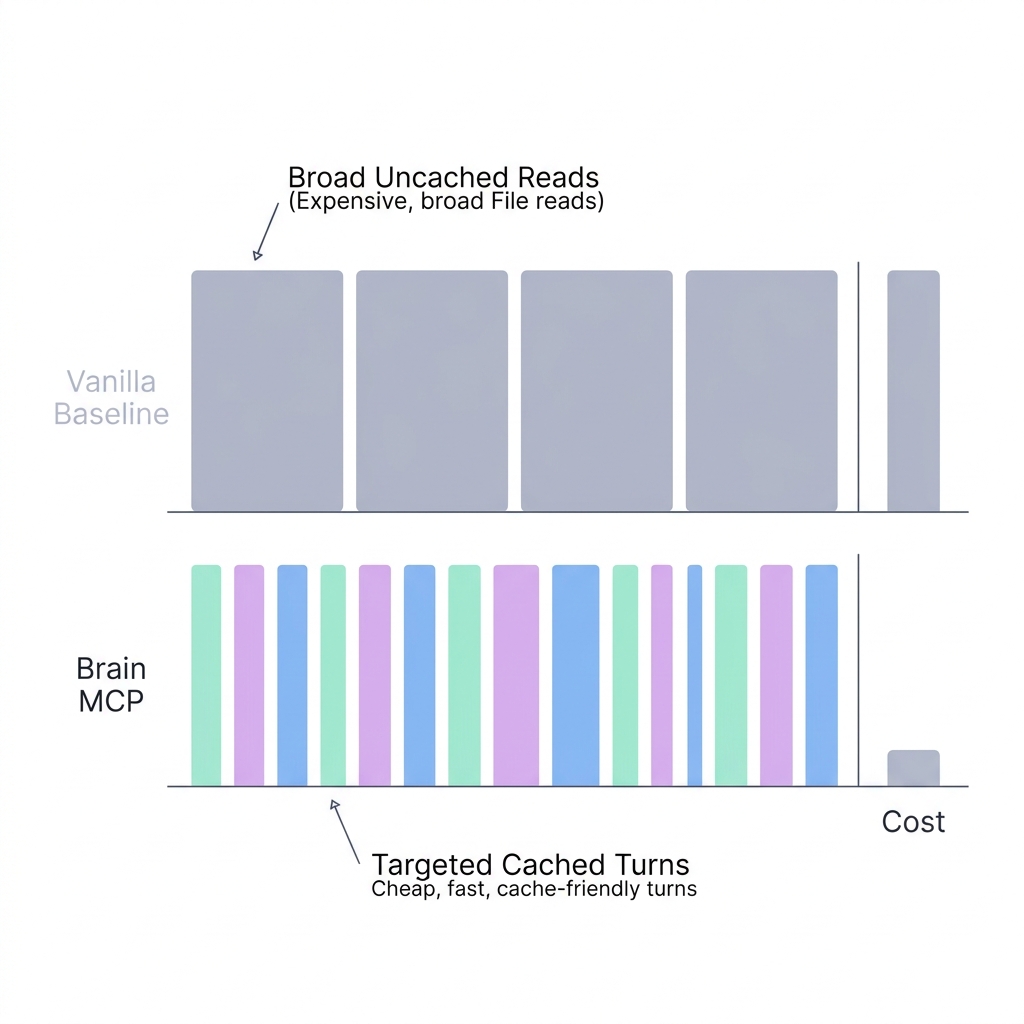
Here’s the result I didn’t expect:
Brain MCP processed 3.5 million effective tokens across 185 agentic turns. Vanilla processed 1.1 million tokens across 57 turns. Brain MCP cost 44% less.
More tokens. More turns. Less money. This seems wrong until you look at the token breakdown.
The Cache Mechanism
Claude Code’s system prompt is approximately 14,000 tokens. On the first turn of a conversation, these tokens are processed at the normal input rate (cache creation, billed at 1.25x). On every subsequent turn, they’re read from cache at 0.1x the normal rate.
The pricing math:
| Token type | Rate (Sonnet) |
|---|---|
| Input (uncached) | $3.00 / 1M |
| Cache creation | $3.75 / 1M (1.25x) |
| Cache read | $0.30 / 1M (0.1x) |
| Output | $15.00 / 1M |
Brain MCP averages 13.2 turns per query. After the first turn, every subsequent turn reads the ~14K system prompt from cache at the discount rate. Its pattern: query brain -> read top result -> refine search terms -> read another result -> synthesize. Each turn adds a small amount of new context (the retrieved document) on top of a large cached prefix.
Vanilla averages 4.4 turns per query (excluding the timed-out query). But each turn does expensive file reads that inject large amounts of new, uncached context. A single Read tool call that returns a 200-line session transcript adds thousands of uncached tokens. A Grep that returns 50 matching lines adds uncached context that must be processed at full price.
The net effect:
| Vanilla | Brain MCP | |
|---|---|---|
| Effective tokens | 1,149,157 | 3,523,380 |
| Cache tokens | 1,126,510 (98.0%) | 3,462,607 (98.3%) |
| Uncached input + output | 22,647 | 60,773 |
| Cost | $5.64 | $3.18 |
Both modes are dominated by cache tokens — 98% or more. But the composition of those cache tokens differs. Brain MCP’s cache tokens are overwhelmingly cache reads (cheap). Vanilla’s cache tokens include more cache creation from the large file contents injected on each turn.
The principle: many cheap, targeted turns beat few expensive, broad turns. Structured retrieval creates cache-friendly access patterns. Brute-force grep doesn’t.
This has implications beyond this benchmark. It suggests that the conventional wisdom of “minimize turns to minimize cost” is wrong for agentic systems with cached system prompts. The right optimization target isn’t turn count — it’s uncached token injection per turn. A 20-turn conversation where each turn adds 500 tokens of targeted retrieval costs less than a 4-turn conversation where each turn adds 5,000 tokens of grep output.
Where Brain MCP Lost
Two queries where vanilla was cheaper:
Query 8 — “How does the Karpathy autoresearch loop pattern work?”
Vanilla: $0.23, 72s, 16 turns. Brain MCP: $0.28, 82s, 14 turns.
The answer lived in local project files that vanilla found via grep in its first few turns. The Karpathy pattern is implemented in the current working directory (tools/autoresearch/), and vanilla Claude Code is excellent at finding things in local files. Brain MCP did a thorough cross-collection search — more comprehensive, but overkill for a question answerable from one file.
Query 14 — “What LLM agent frameworks and patterns have been used across projects?”
Vanilla: $0.28, 119s, 2 turns. Brain MCP: $0.40, 109s, 24 turns.
This is a broad survey question. Brain MCP did the deepest search in the entire benchmark — 24 turns across all four collections, reading extensively about every framework mentioned in any session. It produced a more thorough answer. But the thoroughness wasn’t worth the cost. Vanilla gave a shorter, less detailed answer in just 2 turns, and for a survey question, “good enough” is good enough.
The pattern: Brain MCP loses on two types of queries:
- Single-file answers where the data lives in one obvious location (grep is faster than structured search)
- Broad surveys where exhaustive search costs more than the marginal value of completeness
It wins decisively on targeted recall — “what was decided about X?” — where relevance ranking eliminates wasted reads. That’s 12 of 14 queries in this benchmark.
The Self-Optimizer
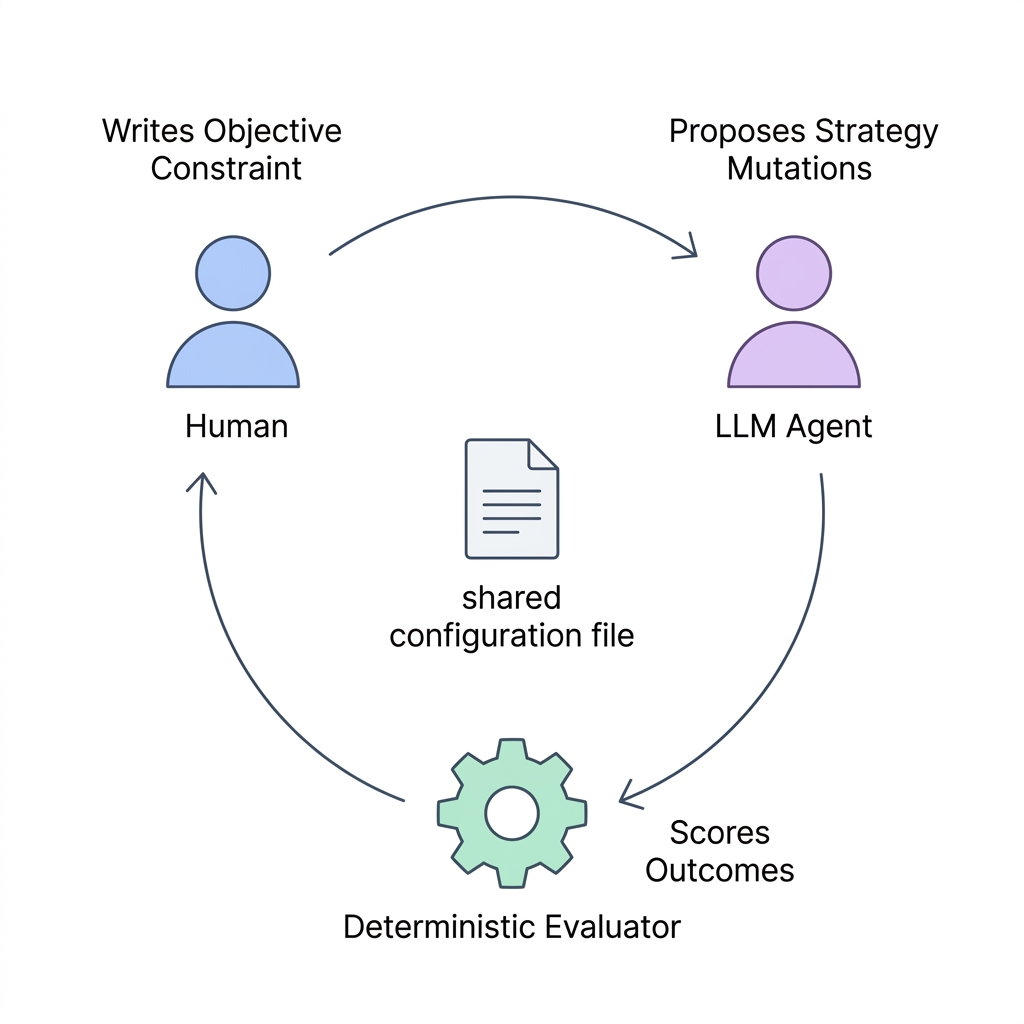
Building the brain was step one. Making it optimize itself was step two.
I implemented a Karpathy-pattern autoresearch loop: one editable file, one immutable runner, one deterministic scorer. The key insight from Karpathy’s design: the human writes the scoring function, the LLM proposes mutations, and the loop is fully autonomous.
The Tripartite Architecture
| File | Role | Who edits it |
|---|---|---|
search_strategy.yaml | The mutable config — search weights, limits, templates | LLM only |
program.md | Operating manual — scoring formula, mutation vocabulary, failure modes | Human only |
runner.py | Immutable loop — eval -> mutate -> keep/revert -> git commit | Never |
evaluator.py | Deterministic scorer — precision + recall_proxy + diversity | Read-only tool |
The separation is critical. The LLM can only touch the strategy file. The human controls the objective function and constraints. The runner enforces the loop. No component can interfere with another.
The Hill Function
The scorer is fully deterministic — no LLM calls needed for evaluation:
def evaluate(query: str, strategy: dict) -> dict:
docs = brain_query(query, strategy)
precision = score_precision(docs, PRECISION_TOP_K) # mean score of top-6
recall = score_recall_proxy(docs) # fraction returning >= 3 docs
diversity = score_diversity(docs) # fraction of 4 collections represented
score = 0.5 * precision + 0.3 * recall + 0.2 * diversity
return {"score": round(score, 4), ...}Three signals, weighted to prioritize precision:
- Precision (weight 0.5): Mean relevance score of the top-6 results, measured using QMD’s reranker score. Uses a fixed window (
PRECISION_TOP_K = 6) regardless of other parameters, preventing the optimizer from gaming the metric by reducing result count. - Recall proxy (weight 0.3): Binary — did the query return at least 3 documents? This is a crude proxy, but it catches the failure mode where over-filtering leaves queries unanswered.
- Diversity (weight 0.2): What fraction of the four collections are represented in the results? This encourages cross-collection retrieval, which matters because different query types need different sources.
The scorer runs all 14 test queries against QMD, computes the aggregate, and returns a single number. No LLM calls. No API costs. This makes it cheap to run hundreds of iterations.
The Mutation Backend
The runner launches Jules (Google’s async coding agent) to propose mutations. Each iteration:
- Runner loads the current strategy + last 10 experiment logs + the operating manual (
program.md) - Jules reads the context, proposes exactly one mutation with a
# HYPOTHESIS:comment - Runner evaluates the mutation against all 14 queries
- If the score improves by > 0.01, keep. Otherwise, revert.
- Git commit either way — the log is the experiment history.
for i in range(1, max_iter + 1):
new_strategy_raw = jules_mutate(strategy_raw, logs)
new_eval = evaluate_all(queries, new_strategy, verbose=True)
delta = new_eval["mean_score"] - best_score
if delta > min_improvement:
decision = "keep"
best_score = new_eval["mean_score"]
else:
decision = "revert"
git_restore()Plateau detection stops the loop after 3 consecutive non-improvements.
What the Optimizer Found
Starting score: 0.6993 (baseline configuration). Final score: 0.7350 after 15+ iterations.
The winning mutations:
limit: 10 -> 40. More results = more collection coverage = higher diversity score.candidate_limit: 10 -> 40. Matching the limit to the full pre-rerank pool prevents good semantic results from being pruned.sub_query_order: Confirmed[lex, vec, hyde]— lex first gets 2x reranking weight, which helps precision.hyde_template: Refined to include domain-specific context (“AI agents, LLM systems, autonomous research loops”).
Dead ends (the optimizer tried and reverted):
sub_query_order: [vec, lex]— no effect (+0.000)candidate_limit: 80— no effect (limit was already at the ceiling)min_score: 0.25or0.20— slight regression (no new collections appeared)limit > 40withcandidate_limit=40— no effect (candidate pool exhausted)
The optimizer also discovered a hard constraint: three queries are stuck at diversity=0.50 because the relevant information only exists in two of four collections (brain + distilled). No search strategy change can fix this — only adding content to kb-wiki or kb-raw would help. This is a genuine ceiling on the score, and the optimizer correctly stopped trying to push past it.
I started the loop and went to sleep. Woke up to a git log of experiments, each with a hypothesis, a score delta, and a keep/revert decision. The agent was doing science while I slept.
Honest Limitations
This benchmark has real flaws. I’m documenting them because the temptation to present clean results is the enemy of useful results.
1. No ground truth scoring. I measured cost, speed, and output volume — not whether the answers were correct or complete. Brain MCP could produce faster, cheaper, wrong answers and this benchmark would call it a win. A rigorous version would score each answer against gold-standard reference answers written by a human.
2. N=1 per condition. No repetitions. LLM outputs are stochastic — the same query can produce different tool call sequences on different runs. One outlier could skew the aggregates. A proper experiment would run 3-5 repetitions per condition and report confidence intervals.
3. Cache order bias. Vanilla ran first, then Brain MCP. This means Brain MCP benefits from any system-level caching (OS page cache, QMD’s internal caches) that vanilla’s run warmed up. More importantly, Claude Code’s prompt cache persists across sessions on the same machine, so Brain MCP may have started with a warmer cache. Randomizing run order across queries would reduce this bias.
4. No baseline. Both modes include Claude Code’s full ~14K token system prompt. I’m measuring the marginal value of brain MCP tools on top of that baseline, not absolute retrieval efficiency. A proper comparison would include a third condition: the naked LLM with no tools at all, answering from parametric knowledge only.
5. Model specificity. Sonnet, not Opus. Tool-use behavior, search strategy, and persistence differ between models. Results may not generalize.
6. Confounded system prompt. The system prompt says “search thoroughly” — this may bias Brain MCP toward more turns (which happen to be cheaper) and vanilla toward broader reads. A neutral prompt might produce different cost dynamics.
7. Evaluator-subject identity. I designed the system, wrote the queries, built the benchmark, and analyzed the results. The usual blinding practices are absent.
A rigorous version of this experiment would: score answers against gold-standard references, run 3+ repetitions per condition per query, randomize condition order, add a naked-LLM baseline, test on multiple models, and have someone else write the test queries.
What I Learned
Memory is not RAG
RAG retrieves documents to answer questions. Memory retrieves decisions, corrections, and rejected approaches to avoid repeating mistakes. The difference is in what you index and how you structure it.
A RAG system over my session transcripts would return noisy conversation fragments. The distillation layer is what turns it into memory — compressing a 2,000-line session into a 30-line artifact with structured sections (Goal, Key Decisions, What Was Rejected, Tags). When the agent queries “what did I decide about auth?”, it gets back a structured decision record, not a raw conversation snippet.
The “What Was Rejected” section is particularly valuable. It prevents the agent from re-exploring dead ends. If a previous session tried and rejected approach X for reason Y, the memory system surfaces that rejection, saving the cost of rediscovering the same dead end.
The temporal dimension matters
A knowledge base is static. A memory system grows with every session. The Stop hook that fires after every Claude Code conversation is the key infrastructure — it makes indexing invisible. If it required manual effort, I’d have stopped at session 20.
The automation has a compounding effect: every session makes the next session better, without any effort from me. Session 590 can query the decisions from session 1. The agent doesn’t just have instructions — it has experience.
Cache economics change the design space
The conventional wisdom is “fewer tokens = cheaper.” This benchmark shows the opposite: more turns with cache-friendly patterns can be cheaper than fewer turns with cold reads.
This has implications for how agentic systems should be designed. Instead of optimizing for turn count, optimize for cache utilization. Structured retrieval tools that return small, targeted results create naturally cache-friendly patterns. File-reading tools that inject large, uncached context don’t.
The 0.1x cache read pricing is the key parameter. At that discount, the break-even point is roughly: if your cache prefix is 10x larger than the new context you’re adding, additional turns are almost free. Brain MCP’s pattern — 14K cached prefix, ~500 tokens of new retrieval per turn — is well below that threshold.
Self-optimization is underrated
The autoresearch loop found a better search strategy than I could have designed by hand. The deterministic hill function (no LLM needed for scoring) makes it cheap to run hundreds of iterations. The Karpathy pattern — one mutable file, one immutable loop, one scoring function — is the simplest architecture that works for autonomous parameter search.
The key design decision: the scoring function must be deterministic and cheap. If you need an LLM to evaluate each iteration, the loop is too expensive to run autonomously. The three-signal hill (precision, recall proxy, diversity) is crude, but it’s computable in seconds with no API calls. That’s what makes overnight autonomous optimization feasible.
The brain MCP system, the benchmark harness, and the autoresearch loop will be open-sourced soon.
Sharad Jain builds agentic AI systems in Bengaluru. He previously built data infrastructure at Meta and founded autoscreen.ai, a production voice AI platform. He writes about agent architecture at sharadja.in.
Previously: The 14K Token Debt: How Your System Prompt Shapes Everything